DevOps, méthode ? Concept ? Métier ? Buzzword ? Nous entendons souvent parler de DevOps, mais il est finalement difficile de savoir à quoi cela correspond réellement. Une recherche sur internet suffit pour se rendre compte qu’il existe un nombre incalculable d’articles sur le sujet.
Dans cet article nous allons vous donner une vision d’ensemble qui vous permettra d’avoir les bases nécessaires pour appréhender plus sereinement DevOps. Nous vous guiderons au travers d’exemples concrets, vous permettant de visualiser les concepts et de franchir le pas. Vous pourrez ainsi passer de la théorie à la pratique !
Préambule
Dev… Ops, un seul mot permettant d’en regrouper deux : « développeur » et « opérateur » . On comprend rapidement que le but premier de DevOps est de réconcilier les uns avec les autres. Lorsqu’un programme entre en production, nous sommes souvent confrontés à deux approches bien différentes. D’un côté, les développeurs cherchent à enrichir le programme en développant de nouvelles fonctionnalités et de l’autre, les opérateurs veulent s’assurer de la stabilité du programme et s’éviter bien des sueurs froides.
Souvent simplement présenté comme une suite d’outils ou décrit comme un métier, « DevOps » est en réalité un courant de pensée beaucoup plus complet.
Il existe plusieurs représentations de ce courant de pensée, mais la plus didactique est axée autour de cinq piliers :
- Réduire les silos entre les organisations.
- Construire de manière graduelle, c’est à dire privilégier une base viable, stable et évolutive mais la plus légère possible.
- Accepter l’erreur comme étant normale, en d’autres termes, anticiper afin de minimiser le coût des pannes et apprendre de ses erreurs.
- Maitriser les outils et l’automatisation.
- Tout mesurer.
Réduire les silos entre les organisations
On devine facilement le sens premier de ce pilier, puisque le but initial est justement de réduire la distance, ou en d’autres termes, de casser les silos entre les développeurs et les opérateurs.
Cependant, nous pouvons également transposer ce concept à une organisation entière, et même à un montage industriel mêlant plusieurs organisations.
Pour appréhender ce pilier, il est essentiel de comprendre que DevOps est étroitement lié à une organisation agile. Il existe même des méthodes agiles, telle que la méthode SAFe, qui sont entièrement dédiées à la mise en place des concepts portés par DevOps. Dans ce cas, la méthode agile, tel un livre de cuisine, nous donne les recettes pour réussir à atteindre les objectifs fixés par chacun des piliers.
Prenons l’exemple de SAFe. SAFe est une méthode permettant de faire de l’agilité « à l’échelle », c’est à dire d’adapter une méthode agile conventionnelle, comme scrum par exemple, afin de coordonner des projets de grande ampleur répartis entre plusieurs équipes de développement.
Nous distinguons dans cette méthode, trois niveaux d’abstractions:
- Equipe (Team en anglais) : constitue le niveau élémentaire dans SAFe, c’est à ce niveau que nous retrouvons les équipes de développement.
- Programme : constitue le niveau intermédiaire dans SAFe, c’est ce niveau qui va permettre de coordonner les différentes équipes.
- Portfolio : constitue le plus haut niveau dans SAFe, c’est à ce niveau que sont décidées les stratégies à plus long terme.
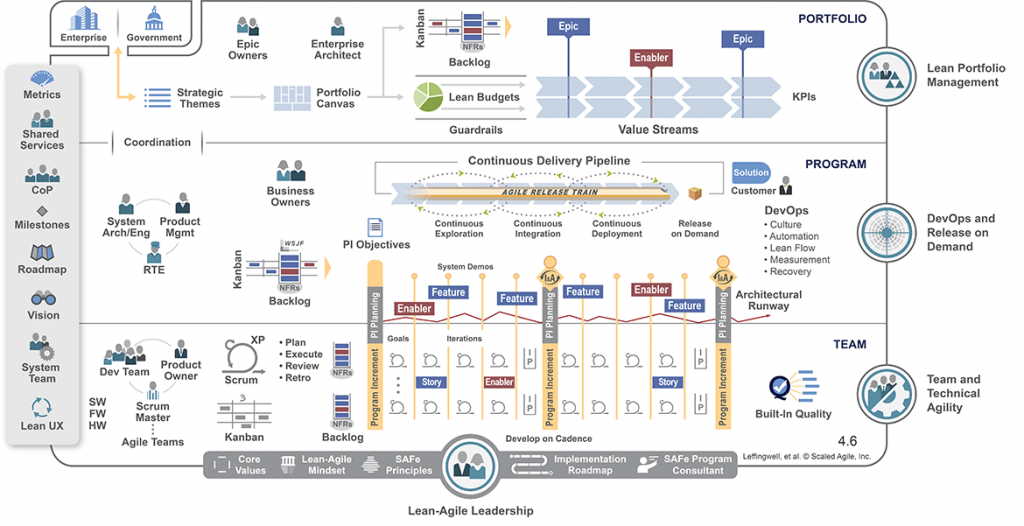
SAFe comme n’importe quelle méthode agile a un séquencement figé et inamovible :
- Itération : il correspond au séquencement du niveau « Team ».
- Incrément : Il correspond au séquencement du niveau « Programme » et comprend en moyenne 5 itérations.
SAFe apporte deux solutions à l’objectif de la réduction des silos entre les organisations.
La première solution est donnée par le « PI planning« . Le Programme Incrément planning, ou PI planning, est un évènement organisé avant chaque début d’incrément qui permet de définir le contenu de l’incrément à venir. Lors du PI planning, l’ensemble des membres des niveaux « TEAM » et »PROGRAMME » ainsi que clients finaux se regroupent tous ensemble dans une salle commune afin de planifier ensemble l’incrément à venir.
Cela permet à toutes les parties prenantes de partager et d’échanger d’abord sur les objectifs, puis sur le contenu de l’incrément. C’est au tout début de cet événement que les clients vont faire part de leur vision et partager leurs priorités. Ensuite, les développeurs des différentes équipes vont pouvoir travailler et échanger afin de construire ensemble le contenu de l’incrément. Il est important de noter que ce sont les développeurs qui s’engagent sur le contours fonctionnel, ce qui veut dire que le management ne peut en aucun cas imposer une charge de travail supplémentaire. La qualité est toujours privilégiée par rapport à la quantité, en d’autres termes, on privilégie le moyen/long terme par rapport au court terme.
La deuxième solution offerte par SAFe est le partage des outils et de la culture. C’est au niveau « PROGRAMME » que sont déployés les outils, incluant :
- des outils de visualisation,
- des outils de mesure,
- des outils d’automatisation.
Ces outils sont partagés pour être utilisés par l’ensemble des parties prenantes.
Construire de manière graduelle
Traditionnellement, lorsque l’on commence un projet, on utilise le cycle en V.
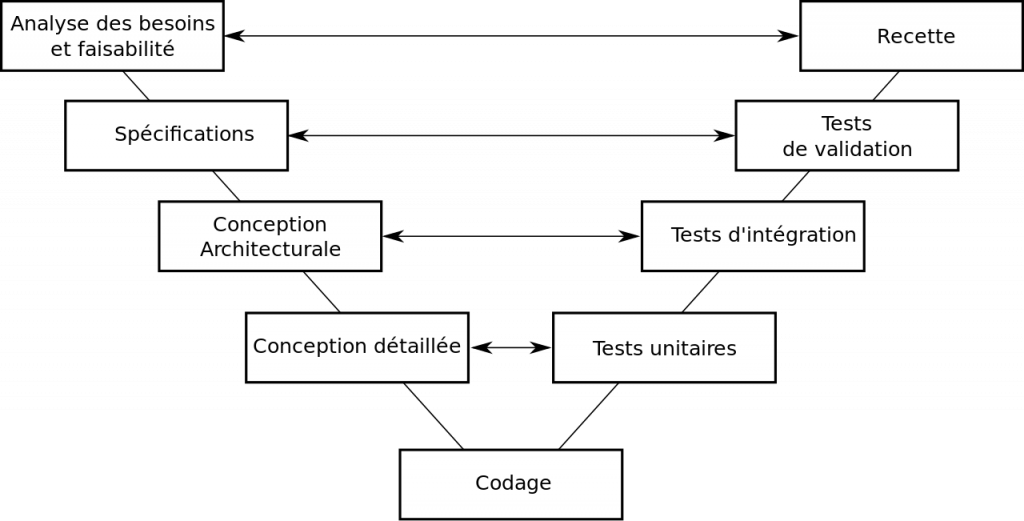
La première étape du cycle en V consiste à analyser les besoins et à faire une étude faisabilité sur le projet en construction. Si l’étude est concluante, le projet pourra se réaliser et la définition des spécifications peut commencer.
C’est à cette étape que les exigences couvrant la totalité du projet sont définies. De ces spécifications, découle la conception architecturale, c’est à dire le découpage du projet en différents composants. Les composants sont alors définis de manière précise, c’est l’étape de la conception détaillée. Une fois la conception terminée, le développement ou codage peut commencer.
C’est à la fin du codage que commence la lente et laborieuse remontée du cycle en V. Cette remontée commence par la phase de tests unitaires qui permettent de tester chacun des composants. Si le résultat des tests unitaires n’est pas conforme à l’attendu, cela signifie que la conception détaillée est défectueuse. Il faut donc la reprendre, puis refaire la partie affectée du développement. Ce mini-cycle doit être recommencé jusqu’à ce que les tests unitaires soient concluants.
C’est maintenant au tour des tests d’intégration. Ces tests valident les interfaces entre les différents composants. Si ces tests ne sont pas conformes, cela signifie que la conception architecturale est défaillante et qu’il faut la mettre à jour. Il faudra alors, successivement, reprendre la conception détaillée, remettre à jour le code, repasser les tests unitaires pour finalement rejouer les tests d’intégrations. Comme pour l’étape précédente, ce cycle doit être recommencé jusqu’à ce que les tests d’intégrations soient concluants.
Une fois les tests d’intégration au vert, les tests de validation peuvent être joués. Ces tests permettent de valider l’ensemble des exigences décrites dans les spécifications. En cas d’échec à cette étape, il faudra revoir les spécifications, puis la conception architecturale, la conception détaillée, le code, les tests unitaires, les tests d’intégration et enfin les tests de validation.
Finalement, une fois les tests de validation concluants, il ne reste plus que la phase de recette. C’est à la recette que le client valide que le produit répond bien à ses attentes et donc à ses besoins. En d’autres termes, dans un cycle en V, le client ne peut valider le produit qu’au tout dernier moment, parfois plusieurs mois, voire plusieurs années après le début du projet. Si le client n’est pas satisfait, il faudra repartir pour un cycle en V complet…
On comprend par ces descriptions que les erreurs faites en début de projet coûtent très cher en fin de projet. Naturellement, on se dit alors qu’il vaut mieux passer beaucoup de temps dans les premières étapes pour s’éviter bien des ennuis plus tard, mais cela augmente le coût et la durée du projet. On voit également que cette organisation n’est pas du tout flexible. Si les besoins changent en cours de projet, alors il faut pratiquement repartir de zéro.

Le cycle en V permet d’organiser les différentes étapes et peut-être très pratique, mais on voit qu’il n’est pas adapté pour des projets de moyenne/grande ampleur. La solution est alors de ne pas vouloir tout construire en une seule fois, mais plutôt de construire le projet de manière graduelle.
Le Minimum Viable Product, ou MVP, est le produit minimum que l’on peut mettre en production. Il est la première pierre à l’édifice, et également la plus petite version fonctionnelle.
Pour bien comprendre, prenons l’exemple de la réalisation d’un gâteau de mariage.
En discutant avec les futurs époux, le pâtissier apprend que ceux-ci désirent un gâteau de type pièce montée, au café, et avec une décoration sur le dessus.
Le pâtissier a donc commencé par définir et réaliser la plus petite version possible du gâteau, et peut rapidement et à moindre coût, convier le couple à une première dégustation.

Après dégustation, le couple est emballé par le gâteau, mais se dit que pour plaire à tous les convives, le gâteau ne devrait pas être à 100% au café. Le pâtissier peut donc faire évoluer son gâteau en prenant en compte les nouveaux besoins.

Le gâteau est très bon, mais finalement, le couple décide d’abandonner le café et de rester sur un glaçage traditionnel. Le couple veut également une décoration représentant un homme et une femme mariés en haut de la pièce montée. Le pâtissier retourne au travail.

Le gâteau est prêt pour le mariage. Les besoins changeants des mariés ont pu être pris en compte par le pâtissier à moindre coût et sans qu’il n’y ait à aucun moment, un risque pour le planning.
Si l’on transpose maintenant cela à un projet informatique, la construction graduelle a plusieurs effets bénéfiques :
- Réduction du Time To Market (TTM), le produit peut être mis en production et être utilisé beaucoup plus tôt.
- Flexibilité : les premiers retours d’expérience arrivent beaucoup plus tôt et les priorités peuvent être redéfinies plus facilement et plus rapidement.
- Réduction des risques planning et coût, une erreur est détectée beaucoup plus tôt permettant une correction anticipée.
Accepter l’erreur comme étant normale
C’est sans doute le pilier le moins naturel à appréhender. Il se découpe en fait en deux points essentiels.
Le premier point est qu’il n’existe pas de projet parfait dans lequel tout se déroule nominalement, que se soit pour la réalisation comme pour les opérations, il faut donc accepter qu’à plusieurs moments dans la vie d’un projet, tout ne se passe pas comme prévu. Plus encore, il faut l’anticiper.
Lors de la phase de réalisation du projet, nous avons vu que l’implémentation graduelle permet de minimiser l’impact des erreurs.
Pour la phase d’opérations, il est également essentiel de prendre en compte ce pilier. Nous pouvons prendre l’exemple du SRE. Le Site Reliability Engineering ou SRE est une manière (autre que SAFe) d’implémenter DevOps. Créée par Google, elle répond à l’acceptation de l’erreur comme étant normal en :
- Définissant des objectifs pour un système. Nommés Service-Level Objectives ou SLO, ces objectifs définissent les caractéristiques voulus pour un système (disponibilité, sécurité, mise à jour,…).
- S’engageant sur un niveau d’objectif. Nommés Service-Level Agreement ou SLA, ce sont en fait des SLO sur lesquels il y a un engagement contractuel.
- Construisant des indicateurs. Nommés Service-Level Indicators ou SLI, ces indicateurs sont essentiels car ils permettent de mesurer les SLO et les SLA.
Concrètement, une équipe peut par exemple se définir comme objectif (SLO) une disponibilité du système de 99.9% par jour. cela signifie que le système doit être disponible un peu plus 23h58 par tranche de 24h.
L’équipe peut, en parallèle, s’engager (SLA) sur une disponibilité de 99.5% par an, c’est à dire un peu moins de 2 jours d’indisponibilité par an.
Il faut maintenant créer le/les indicateurs (SLI) pour mesurer l’objectif (SLO) et l’engagement (SLA). Ces indicateurs pourraient être, pour un site web par exemple:
- le nombre de minutes où le site est en ligne par jour pour mesurer le SLO,
- le nombre de minutes par an où le site en ligne, permettant de mesurer le SLA.
Si, au cours d’une journée, le site est inaccessible plus de 2 minutes, une alerte sera remontée automatiquement car l’objectif (SLO) ne sera plus respecté. Le fait d’avoir un SLO plus contraignant que le SLA permet à l’équipe d’agir rapidement tout en ayant une marge confortable pour ne pas rompre l’engagement.
Cela permet également aux équipes d’opérationde mener des tests d’une nature un peu particulière. Nommés « Chaos Monkey » chez Netflix ou « DiRT » pour Disaster and Recovery Tests chez Google, ces tests visent à mettre volontairement à mal l’environnement de production afin de mesurer la réactivité et la préparation des équipes d’opération.
Ces tests peuvent consister, pour Netflix par exemple, à éteindre volontairement un datacenter complet, afin de mesurer l’impact qu’aurait cette panne sur la production.
L’anticipation permanente de l’erreur pour en minimiser les impacts doit être une recherche permanente, ce qui nous emmène vers le second point: le partage des responsabilités.
Si un problème survient, il ne faut pas chercher un responsable, un fusible que l’on pourrait faire sauter pour le remplacer par un autre qui pourrait tout autant faire la même erreur. Il est plutôt préférable d’analyser en profondeur les évènements qui ont conduit à cette erreur, et de mettre en place les mesures nécessaires pour s’assurer que cette erreur ne pourra jamais être reproduite. La responsabilité doit être partagée entre toutes les parties prenantes du projet.
Prenons un exemple, imaginons qu’un opérateur au travers un portail d’administration supprime malencontreusement une base de données et qu’aucune sauvegarde de cette base de données ne soit disponible. Que retenir ?
Nous pourrions retenir uniquement la faute faite par l’opérateur, mais nous n’aurions alors aucune garantie que le problème ne se reproduise pas. A l’inverse, nous aurions plutôt la quasi certitude que ce problème se reproduirait un jour.
Nous pourrions par contre noter que :
- Une base de données doit toujours avoir une sauvegarde à jour disponible (responsabilité opérateurs),
- le portail aurait dû avoir un message de confirmation explicitant les risques (responsabilité développeurs/ architectes),
- Seuls les administrateurs devraient avoir accès à cette fonctionnalité (process),
- …
Ce partage des responsabilités implique de fait, de ne pas désigner de responsable en cas d’erreur, mais il est essentiel d’aller encore plus loin. L’acceptation de l’erreur comme étant normale, doit pousser toutes les parties prenantes à chercher et à trouver les problèmes le plus rapidement possible afin de mettre en place des correctifs qui permettront d’avoir le système le plus stable possible tout en étant évolutif.
Il ne faut donc pas essayer d’éviter de commettre ne serait-ce qu’une seule erreur comme on en aurait intuitivement l’envie, mais plutôt essayer d’échouer le plus tôt possible pour en tirer les bonnes conclusions. Il ne faut pas oublier, comme nous l’avons vu avec l’implémentation graduelle qu’une erreur détectée tardivement coûte très cher!
Maitriser les outils et l’automatisation
Toujours dans le but de diminuer le Time To Market, les risques et donc le coût, il est essentiel de mettre en place une suite d’outils et de process d’automatisation le plus tôt possible dans la mise en place du projet. Comme nous l’avons vu pour le pilier « Réduire les silos entre les organisations », les outils doivent être partagés par l’ensemble des parties prenantes du projet et doivent permettre de :
- visualiser et alerter sur :
- Les objectifs et les engagements,
- L’avancement de chacune des équipes,
- L’état du système,
- …
- Automatiser :
- le build : c’est à dire la compilation et le packaging des applications,
- Le déploiement des applications,
- les tests unitaires, les tests d’intégrations, les tests de validation ainsi que la création de rapport et l’envoi d’alertes en cas d’erreur,
- La livraison de la solution complète.
Tout mesurer
Pour comprendre ce pilier, deux définitions sont essentielles :
Observabilité : C’est la capacité d’un site à fournir des données permettant de